Goroutine to Improve Golang based Kafka Transformer Throughput
This post is the golang version of “Utilise Multiprocessing to Improve Python Kafka Transformer Throughput” post. I suggest you to read it first.
Prepare The Kafka Broker
I will use the same method as last post.
Make sure
gitanddocker-composeis installed.
git clone https://github.com/rochimfn/compose-collection.git
cd compose-collection/redpanda
docker-compose up -d # or docker compose up -d
You can clean up redpanda data by running
docker-compose down -vbefore bringing up the service.
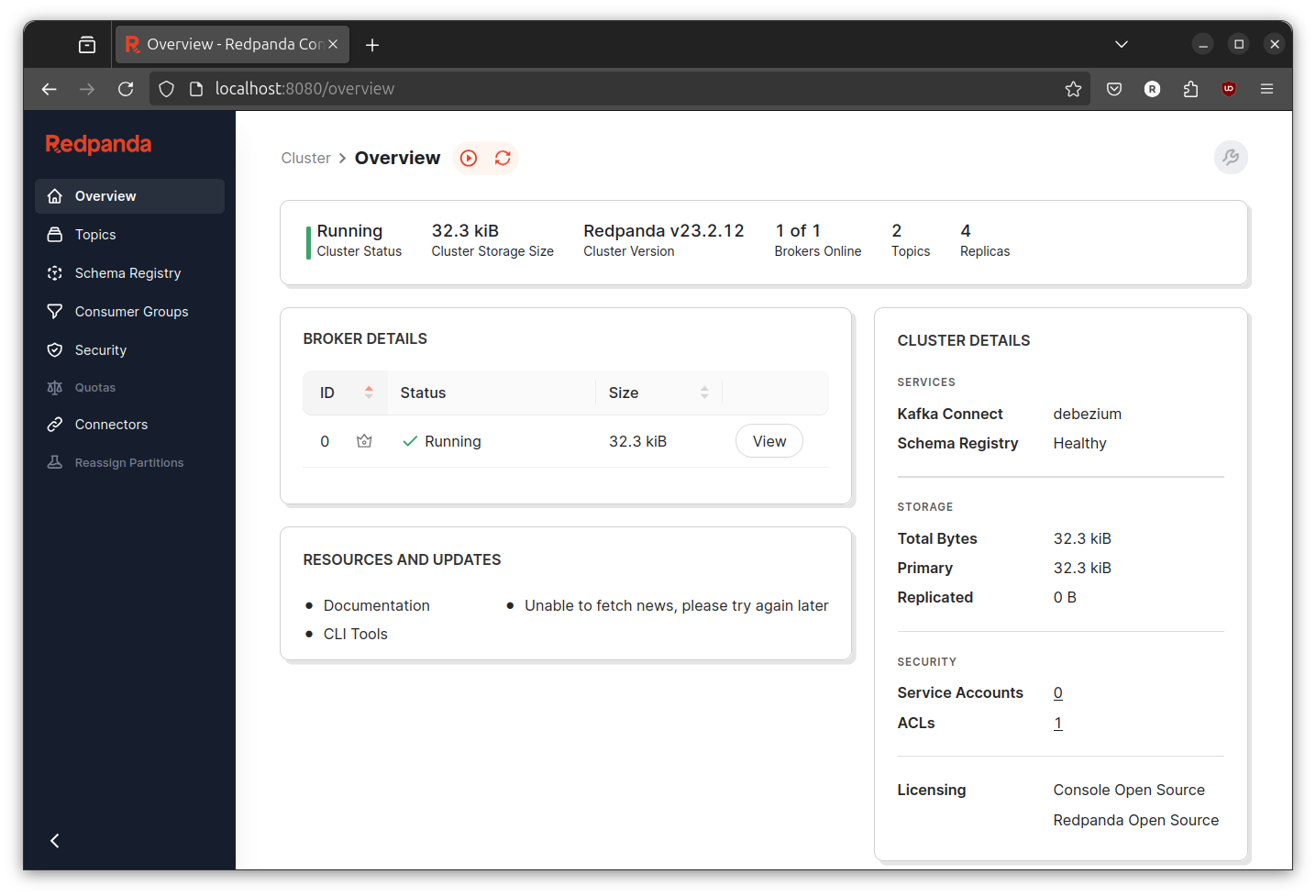
Go to http://localhost:8080/overview verify redpanda is running.
Prepare The Event Generator
I will use the same as last post.
git clone https://github.com/rochimfn/go-mock-name-kafka.git
cd go-mock-name-kafka
go run main.go
Hit ctrl+c to stop.
The connection details is at line 15-19. The Golang version is 1.23.4.
Built Golang Transformer: The Serial Implementation
The transformer will do the same job as last post:
- consume the event,
- generate the md5 hash of the event,
- add the generated md5 hash into the event, and
- produce the event into the different topic
Init the project:
mkdir golang-kafka-serial-transformer
cd golang-kafka-serial-transformer/
go mod init github.com/rochimfn/golang-kafka-serial-transformer
go get -u github.com/confluentinc/confluent-kafka-go/kafka
Create main.go file and here is the code for the serial way:
package main
import (
"crypto/md5"
"encoding/json"
"fmt"
"log"
"os"
"os/signal"
"syscall"
"time"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
var topic = "name_stream"
var destinationTopic = "name_stream_serial_transformed"
var kafkaConfigConsumer = kafka.ConfigMap{
"bootstrap.servers": "localhost:19092",
"group.id": "consumer_golang_serial",
}
var kafkaConfigProducer = kafka.ConfigMap{
"bootstrap.servers": "localhost:19092",
"acks": "all",
}
var produceRetryLimit = 3
type NameEvent struct {
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
Hash string `json:"hash"`
}
func handleUnexpectedError(err error) {
if err != nil {
log.Fatalf("unexpected error occured: %s \n", err)
}
}
func hashMessage(key []byte, value []byte) ([]byte, []byte) {
event := NameEvent{}
err := json.Unmarshal(value, &event)
handleUnexpectedError(err)
event.Hash = fmt.Sprintf("%x", md5.Sum(value))
value, err = json.Marshal(event)
handleUnexpectedError(err)
return key, value
}
func ack(p *kafka.Producer) {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
log.Printf("Failed to deliver message: %s: %s\n", string(ev.Value), ev.TopicPartition.Error)
} else {
log.Printf("Successfully produced message {%s} into {%s}[{%d}]@{%s}\n",
string(ev.Value), *ev.TopicPartition.Topic, ev.TopicPartition.Partition, ev.TopicPartition.Offset.String())
}
}
}
}
func flushAll(p *kafka.Producer) {
for unlfushed := p.Flush(30 * 1000); unlfushed > 0; {
}
}
func consumeLoop(quit <-chan os.Signal) {
c, err := kafka.NewConsumer(&kafkaConfigConsumer)
handleUnexpectedError(err)
defer c.Close()
p, err := kafka.NewProducer(&kafkaConfigProducer)
handleUnexpectedError(err)
go ack(p)
defer p.Close()
defer flushAll(p)
err = c.SubscribeTopics([]string{topic}, nil)
handleUnexpectedError(err)
for {
select {
case <-quit:
return
default:
msg, err := c.ReadMessage(time.Second)
if err != nil && err.(kafka.Error).Code() == kafka.ErrTimedOut {
time.Sleep(1 * time.Second)
continue
}
handleUnexpectedError(err)
key, value := hashMessage(msg.Key, msg.Value)
numRetry := 0
message := &kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &destinationTopic, Partition: kafka.PartitionAny},
Key: key, Value: value,
}
for err = p.Produce(message, nil); err != nil && numRetry < produceRetryLimit; {
numRetry += 1
log.Printf("error produce %s retrying after flush\n", err)
flushAll(p)
}
}
}
}
func main() {
quitChan := make(chan os.Signal, 1)
signal.Notify(quitChan, os.Interrupt, syscall.SIGTERM)
consumeLoop(quitChan)
}
The code is slightly modified version of getting started guide from confluent.
The top part is responsible for configuration.
var topic = "name_stream"
var destinationTopic = "name_stream_serial_transformed"
var kafkaConfigConsumer = kafka.ConfigMap{
"bootstrap.servers": "localhost:19092",
"group.id": "consumer_golang_serial",
}
var kafkaConfigProducer = kafka.ConfigMap{
"bootstrap.servers": "localhost:19092",
"acks": "all",
}
var produceRetryLimit = 3
I use single struct for deserialize incoming event from kafka and to serialize before going back into kafka.
type NameEvent struct {
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
Hash string `json:"hash"`
}
Ideally error should be retried or handled carefully, but I will make it simple here and just exit when error occured.
func handleUnexpectedError(err error) {
if err != nil {
log.Fatalf("unexpected error occured: %s \n", err)
}
}
The hashMessage function is responsible for calculate the hashes and add it to the event value.
func hashMessage(key []byte, value []byte) ([]byte, []byte) {
event := NameEvent{}
err := json.Unmarshal(value, &event)
handleUnexpectedError(err)
event.Hash = fmt.Sprintf("%x", md5.Sum(value))
value, err = json.Marshal(event)
handleUnexpectedError(err)
return key, value
}
The consumeLoop is where the main logic live. The function will consume event from kafka, call to hash function with the event, than send the result to the producer.
func ack(p *kafka.Producer) {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
log.Printf("Failed to deliver message: %s: %s\n", string(ev.Value), ev.TopicPartition.Error)
} else {
log.Printf("Successfully produced message {%s} into {%s}[{%d}]@{%s}\n",
string(ev.Value), *ev.TopicPartition.Topic, ev.TopicPartition.Partition, ev.TopicPartition.Offset.String())
}
}
}
}
func flushAll(p *kafka.Producer) {
for unlfushed := p.Flush(30 * 1000); unlfushed > 0; {
}
}
func consumeLoop(quit <-chan os.Signal) {
c, err := kafka.NewConsumer(&kafkaConfigConsumer)
handleUnexpectedError(err)
defer c.Close()
p, err := kafka.NewProducer(&kafkaConfigProducer)
handleUnexpectedError(err)
go ack(p)
defer p.Close()
defer flushAll(p)
err = c.SubscribeTopics([]string{topic}, nil)
handleUnexpectedError(err)
for {
select {
case <-quit:
return
default:
msg, err := c.ReadMessage(time.Second)
if err != nil && err.(kafka.Error).Code() == kafka.ErrTimedOut {
time.Sleep(1 * time.Second)
continue
}
handleUnexpectedError(err)
key, value := hashMessage(msg.Key, msg.Value)
numRetry := 0
message := &kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &destinationTopic, Partition: kafka.PartitionAny},
Key: key, Value: value,
}
for err = p.Produce(message, nil); err != nil && numRetry < produceRetryLimit; {
numRetry += 1
log.Printf("error produce %s retrying after flush\n", err)
flushAll(p)
}
}
}
}
The main function will setup the quit signal and call the consumeLoop.
func main() {
quitChan := make(chan os.Signal, 1)
signal.Notify(quitChan, os.Interrupt, syscall.SIGTERM)
consumeLoop(quitChan)
}
Before run the program, run go mod tidy to convert the confluent-kafka-go dependecy status from indirect to direct. Also remember to delete the topic if its already there from previous post.
Run the event generator:
cd go-mock-name-kafka
go run main.go
Run the program:
cd golang-kafka-serial-transformer/
go run main.go
Check the consumer lag on the redpanda console. Goto http://localhost:8080/ > Topics page > name_stream topics > Consumers.
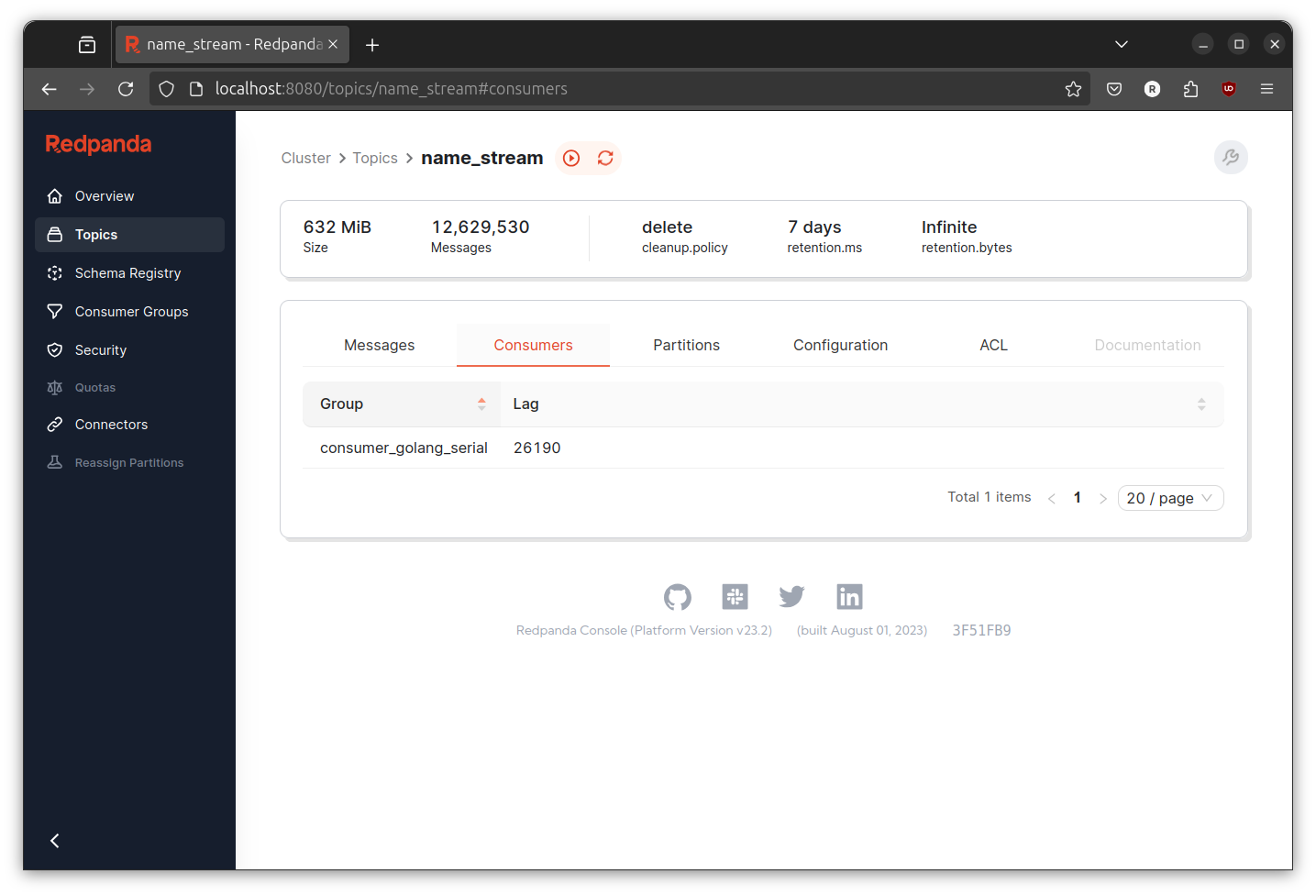
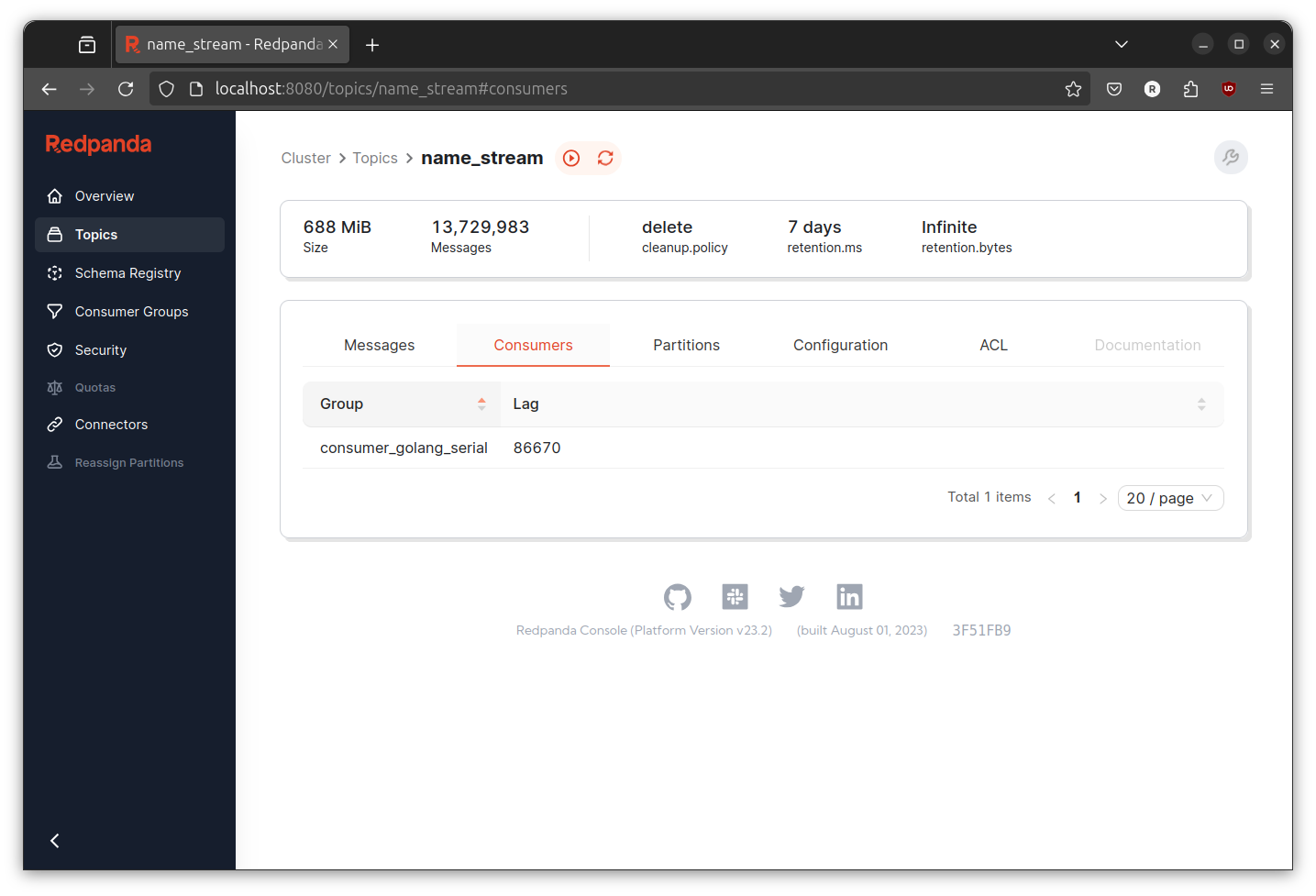
The throughput is really good, at least if we compared it to the python version. But that is not my goal. My goal is to use goroutine to beat the throughput of the serial implementation. And better yet, to beat the produce rate of the event generator. Also for this post (and last post), I will use the consumer lag as the only one indicator. I am too lazy to check on another metrics or too measure everything.
Built Golang Transformer: The Pipeline Pattern
I know at least two pattern to use goroutine, pipeline and worker. I will go with pipeline first. Just like the last post, I will split the program into three stages, consumer, hasher, and producer.
Create another project based:
mkdir golang-kafka-concurrent-transformer-pipeline
cd golang-kafka-concurrent-transformer-pipeline/
go mod init github.com/rochimfn/ggolang-kafka-concurrent-transformer-pipeline
go get -u github.com/confluentinc/confluent-kafka-go/kafka
The consumer stage still look like the serial implementation. The difference is instead of calling the hasher and producer directly, the consumer will put the event into channel.
Here is the consumer stage implementation:
func consumer(quitChan <-chan os.Signal, consumerChan chan<- kafka.Message) {
c, err := kafka.NewConsumer(&kafkaConfigConsumer)
handleUnexpectedError(err)
defer c.Close()
defer close(consumerChan)
err = c.SubscribeTopics([]string{topic}, nil)
handleUnexpectedError(err)
for {
select {
case <-quitChan:
return
default:
msg, err := c.ReadMessage(time.Second)
if err != nil && err.(kafka.Error).Code() == kafka.ErrTimedOut {
log.Println("timeout")
time.Sleep(1 * time.Second)
continue
}
handleUnexpectedError(err)
consumerChan <- *msg
}
}
}
The hasher stage will consume event coming from consumer through channel. The hasher will hash the event put it into second channel. The hasher also responsible for closing the second channel if the first channel is closed by the consumer.
Here is the hasher implementation:
func hasher(consumerChan <-chan kafka.Message, hasherChan chan<- kafka.Message) {
for message := range consumerChan {
event := NameEvent{}
err := json.Unmarshal(message.Value, &event)
handleUnexpectedError(err)
event.Hash = fmt.Sprintf("%x", md5.Sum(message.Value))
message.Value, err = json.Marshal(event)
handleUnexpectedError(err)
hasherChan <- message
}
close(hasherChan)
}
The last stage, producer stage, will produce the event coming from hasher until the channel is closed.
func ack(p *kafka.Producer) {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
log.Printf("Failed to deliver message: %s: %s\n", string(ev.Value), ev.TopicPartition.Error)
} else {
log.Printf("Successfully produced message {%s} into {%s}[{%d}]@{%s}\n",
string(ev.Value), *ev.TopicPartition.Topic, ev.TopicPartition.Partition, ev.TopicPartition.Offset.String())
}
}
}
}
func flushAll(p *kafka.Producer) {
for unlfushed := p.Flush(30 * 1000); unlfushed > 0; {
}
}
func producer(hasherChan <-chan kafka.Message) {
p, err := kafka.NewProducer(&kafkaConfigProducer)
handleUnexpectedError(err)
go ack(p)
defer p.Close()
defer flushAll(p)
for message := range hasherChan {
numRetry := 0
msg := &kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &destinationTopic, Partition: kafka.PartitionAny},
Key: message.Key, Value: message.Value,
}
for err = p.Produce(msg, nil); err != nil && numRetry < produceRetryLimit; {
numRetry += 1
log.Printf("error produce %s retrying after flush\n", err)
flushAll(p)
}
}
}
Here is the full code:
package main
import (
"crypto/md5"
"encoding/json"
"fmt"
"log"
"os"
"os/signal"
"sync"
"syscall"
"time"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
var topic = "name_stream"
var destinationTopic = "name_stream_concurrent_transformed"
var kafkaConfigConsumer = kafka.ConfigMap{
"bootstrap.servers": "localhost:19092",
"group.id": "consumer_golang_concurrent",
}
var kafkaConfigProducer = kafka.ConfigMap{
"bootstrap.servers": "localhost:19092",
"acks": "all",
"queue.buffering.max.messages": 1000 * 1000,
}
var produceRetryLimit = 3
type NameEvent struct {
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
Hash string `json:"hash"`
}
func handleUnexpectedError(err error) {
if err != nil {
log.Fatalf("unexpected error occured: %s \n", err)
}
}
func consumer(quitChan <-chan os.Signal, consumerChan chan<- kafka.Message) {
c, err := kafka.NewConsumer(&kafkaConfigConsumer)
handleUnexpectedError(err)
defer c.Close()
defer close(consumerChan)
err = c.SubscribeTopics([]string{topic}, nil)
handleUnexpectedError(err)
for {
select {
case <-quitChan:
return
default:
msg, err := c.ReadMessage(time.Second)
if err != nil && err.(kafka.Error).Code() == kafka.ErrTimedOut {
log.Println("timeout")
time.Sleep(1 * time.Second)
continue
}
handleUnexpectedError(err)
consumerChan <- *msg
}
}
}
func hasher(consumerChan <-chan kafka.Message, hasherChan chan<- kafka.Message) {
for message := range consumerChan {
event := NameEvent{}
err := json.Unmarshal(message.Value, &event)
handleUnexpectedError(err)
event.Hash = fmt.Sprintf("%x", md5.Sum(message.Value))
message.Value, err = json.Marshal(event)
handleUnexpectedError(err)
hasherChan <- message
}
close(hasherChan)
}
func ack(p *kafka.Producer) {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
log.Printf("Failed to deliver message: %s: %s\n", string(ev.Value), ev.TopicPartition.Error)
} else {
log.Printf("Successfully produced message {%s} into {%s}[{%d}]@{%s}\n",
string(ev.Value), *ev.TopicPartition.Topic, ev.TopicPartition.Partition, ev.TopicPartition.Offset.String())
}
}
}
}
func flushAll(p *kafka.Producer) {
for unlfushed := p.Flush(30 * 1000); unlfushed > 0; {
}
}
func producer(hasherChan <-chan kafka.Message) {
p, err := kafka.NewProducer(&kafkaConfigProducer)
handleUnexpectedError(err)
go ack(p)
defer p.Close()
defer flushAll(p)
for message := range hasherChan {
numRetry := 0
msg := &kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &destinationTopic, Partition: kafka.PartitionAny},
Key: message.Key, Value: message.Value,
}
for err = p.Produce(msg, nil); err != nil && numRetry < produceRetryLimit; {
numRetry += 1
log.Printf("error produce %s retrying after flush\n", err)
flushAll(p)
}
}
}
func main() {
quitChan := make(chan os.Signal, 1)
signal.Notify(quitChan, os.Interrupt, syscall.SIGTERM)
consumerChan := make(chan kafka.Message, 1000*1000)
hasherChan := make(chan kafka.Message, 1000*1000)
wg := sync.WaitGroup{}
wg.Add(3)
go func() {
consumer(quitChan, consumerChan)
wg.Done()
}()
go func() {
hasher(consumerChan, hasherChan)
wg.Done()
}()
go func() {
producer(hasherChan)
wg.Done()
}()
wg.Wait()
}
Run go mod tidy to set confluent-kafka-go as direct dependency before the first run. And remember to clean up the topic before running the event generator and the transformer.
Run the event generator:
cd go-mock-name-kafka
go run main.go
Run the program:
cd golang-kafka-concurrent-transformer-pipeline
go run main.go
Let both run for sometime and inspect the consumer lag at redpanda console.
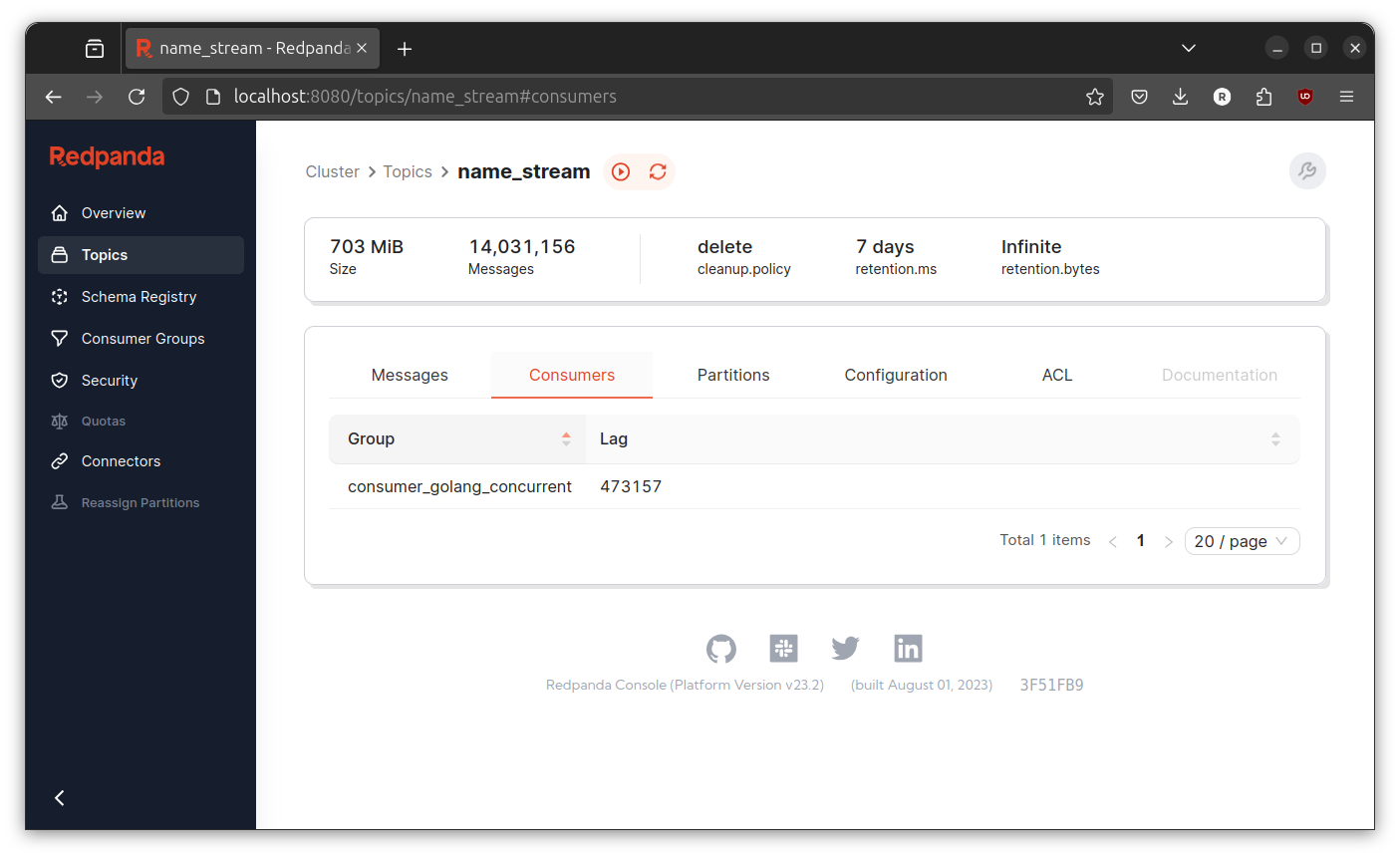
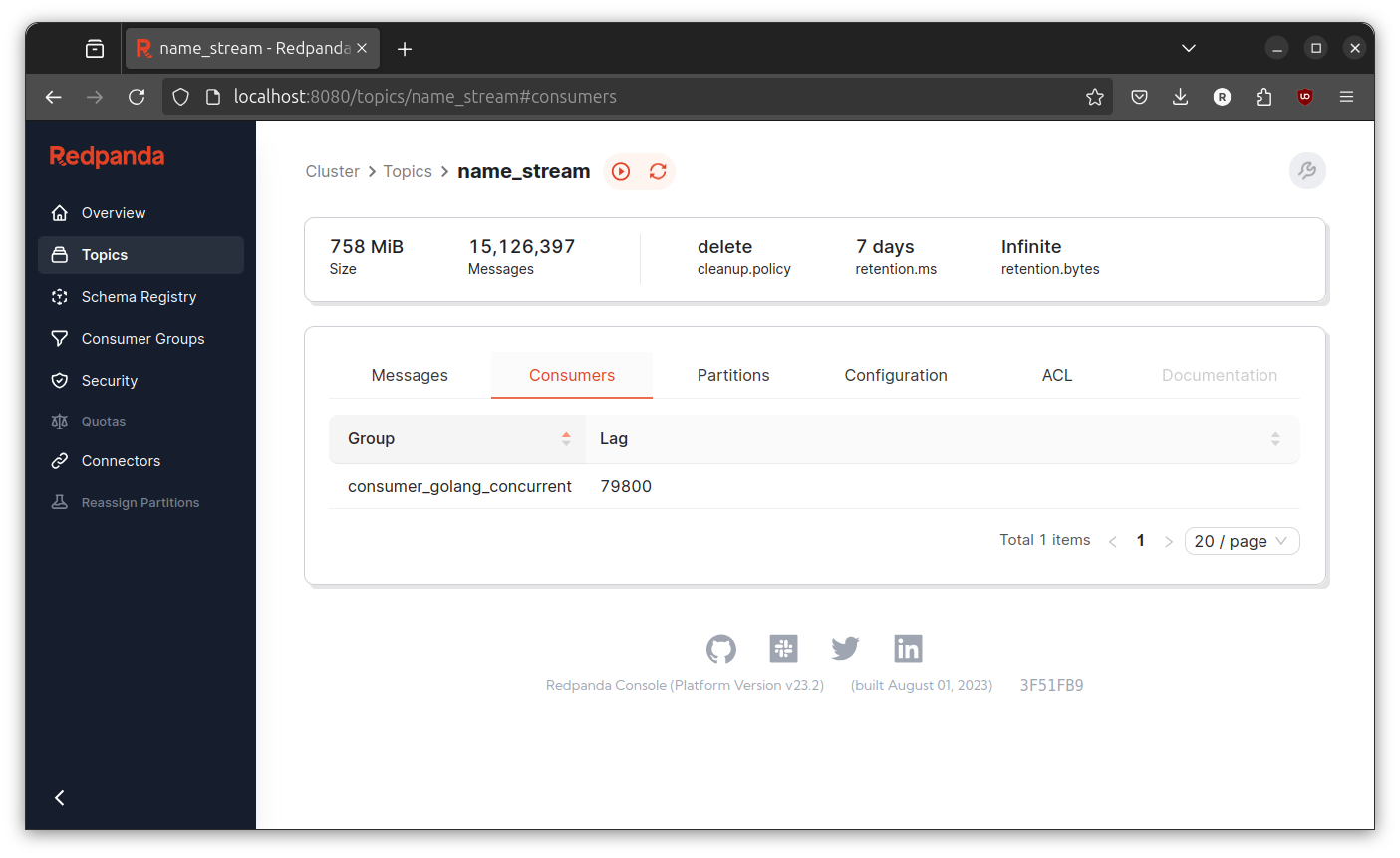
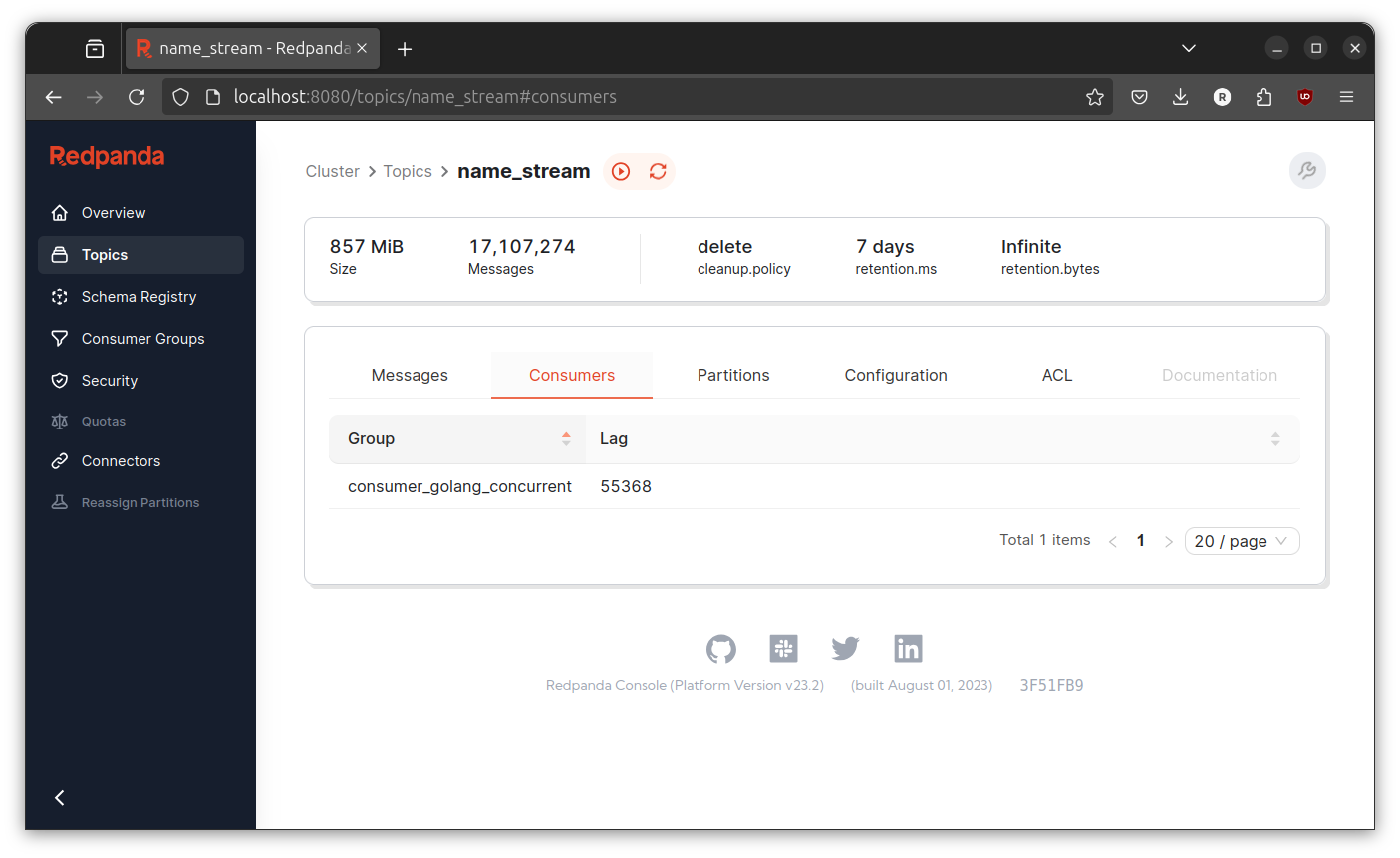
Sometimes the consumer lag going high, sometimes its going low. The only noticeable difference is this version never going above 1000000 consumer lag. But, I don’t exactly sure if this implementation is better or not. Anyway, lets proceed to next implementation.
Built Golang Transformer: The Worker Pattern
The worker pattern consist of a single task pool and multiple worker. For this case the task pool will be a channel. The one responsible to fill the task poll is consumer. A single worker will consist of the hasher and the producer. I can make the consumer to be part of a worker. But it is not fit with the use case, I only deal with one partition. Kafka only allow maximum one consumer per partition. We will go with combination of hasher and producer as worker.
Create another project:
mkdir golang-kafka-concurrent-transformer-worker
cd golang-kafka-concurrent-transformer-worker/
go mod init github.com/rochimfn/ggolang-kafka-concurrent-transformer-worker
go get -u github.com/confluentinc/confluent-kafka-go/kafka
Create a variable to control the number of worker:
var numOfWorker = 4
Merge the hasher and the producer into single worker:
func worker(consumerChan <-chan kafka.Message) {
p, err := kafka.NewProducer(&kafkaConfigProducer)
handleUnexpectedError(err)
go ack(p)
defer p.Close()
defer flushAll(p)
for message := range consumerChan {
event := NameEvent{}
err := json.Unmarshal(message.Value, &event)
handleUnexpectedError(err)
event.Hash = fmt.Sprintf("%x", md5.Sum(message.Value))
message.Value, err = json.Marshal(event)
handleUnexpectedError(err)
numRetry := 0
msg := &kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &destinationTopic, Partition: kafka.PartitionAny},
Key: message.Key, Value: message.Value,
}
for err = p.Produce(msg, nil); err != nil && numRetry < produceRetryLimit; {
numRetry += 1
log.Printf("error produce %s retrying after flush\n", err)
flushAll(p)
}
}
}
Handle the worker creation in main function:
func main() {
quitChan := make(chan os.Signal, 1)
signal.Notify(quitChan, os.Interrupt, syscall.SIGTERM)
consumerChan := make(chan kafka.Message, 1000*1000)
wg := sync.WaitGroup{}
wg.Add(1 + numOfWorker)
go func() {
consumer(quitChan, consumerChan)
wg.Done()
}()
for i := 0; i < numOfWorker; i++ {
go func() {
worker(consumerChan)
wg.Done()
}()
}
wg.Wait()
}
Here is the full code:
package main
import (
"crypto/md5"
"encoding/json"
"fmt"
"log"
"os"
"os/signal"
"sync"
"syscall"
"time"
"github.com/confluentinc/confluent-kafka-go/kafka"
)
var topic = "name_stream"
var destinationTopic = "name_stream_concurrent_transformed"
var kafkaConfigConsumer = kafka.ConfigMap{
"bootstrap.servers": "localhost:19092",
"group.id": "consumer_golang_concurrent",
}
var kafkaConfigProducer = kafka.ConfigMap{
"bootstrap.servers": "localhost:19092",
"acks": "all",
"queue.buffering.max.messages": 1000 * 1000,
}
var produceRetryLimit = 3
var numOfWorker = 4
type NameEvent struct {
FirstName string `json:"first_name"`
LastName string `json:"last_name"`
Hash string `json:"hash"`
}
func handleUnexpectedError(err error) {
if err != nil {
log.Fatalf("unexpected error occured: %s \n", err)
}
}
func consumer(quitChan <-chan os.Signal, consumerChan chan<- kafka.Message) {
c, err := kafka.NewConsumer(&kafkaConfigConsumer)
handleUnexpectedError(err)
defer c.Close()
defer close(consumerChan)
err = c.SubscribeTopics([]string{topic}, nil)
handleUnexpectedError(err)
for {
select {
case <-quitChan:
return
default:
msg, err := c.ReadMessage(time.Second)
if err != nil && err.(kafka.Error).Code() == kafka.ErrTimedOut {
log.Println("timeout")
time.Sleep(1 * time.Second)
continue
}
handleUnexpectedError(err)
consumerChan <- *msg
}
}
}
func ack(p *kafka.Producer) {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
log.Printf("Failed to deliver message: %s: %s\n", string(ev.Value), ev.TopicPartition.Error)
} else {
log.Printf("Successfully produced message {%s} into {%s}[{%d}]@{%s}\n",
string(ev.Value), *ev.TopicPartition.Topic, ev.TopicPartition.Partition, ev.TopicPartition.Offset.String())
}
}
}
}
func flushAll(p *kafka.Producer) {
for unlfushed := p.Flush(30 * 1000); unlfushed > 0; {
}
}
func worker(consumerChan <-chan kafka.Message) {
p, err := kafka.NewProducer(&kafkaConfigProducer)
handleUnexpectedError(err)
go ack(p)
defer p.Close()
defer flushAll(p)
for message := range consumerChan {
event := NameEvent{}
err := json.Unmarshal(message.Value, &event)
handleUnexpectedError(err)
event.Hash = fmt.Sprintf("%x", md5.Sum(message.Value))
message.Value, err = json.Marshal(event)
handleUnexpectedError(err)
numRetry := 0
msg := &kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &destinationTopic, Partition: kafka.PartitionAny},
Key: message.Key, Value: message.Value,
}
for err = p.Produce(msg, nil); err != nil && numRetry < produceRetryLimit; {
numRetry += 1
log.Printf("error produce %s retrying after flush\n", err)
flushAll(p)
}
}
}
func main() {
quitChan := make(chan os.Signal, 1)
signal.Notify(quitChan, os.Interrupt, syscall.SIGTERM)
consumerChan := make(chan kafka.Message, 1000*1000)
wg := sync.WaitGroup{}
wg.Add(1 + numOfWorker)
go func() {
consumer(quitChan, consumerChan)
wg.Done()
}()
for i := 0; i < numOfWorker; i++ {
go func() {
worker(consumerChan)
wg.Done()
}()
}
wg.Wait()
}
Run go mod tidy for the first time. Clean up the topics from redpanda console. And we are ready to go.
Run the event generator:
cd go-mock-name-kafka
go run main.go
Run the program:
cd golang-kafka-concurrent-transformer-pipeline
go run main.go
Check the number of consumer lag at redpanda console.
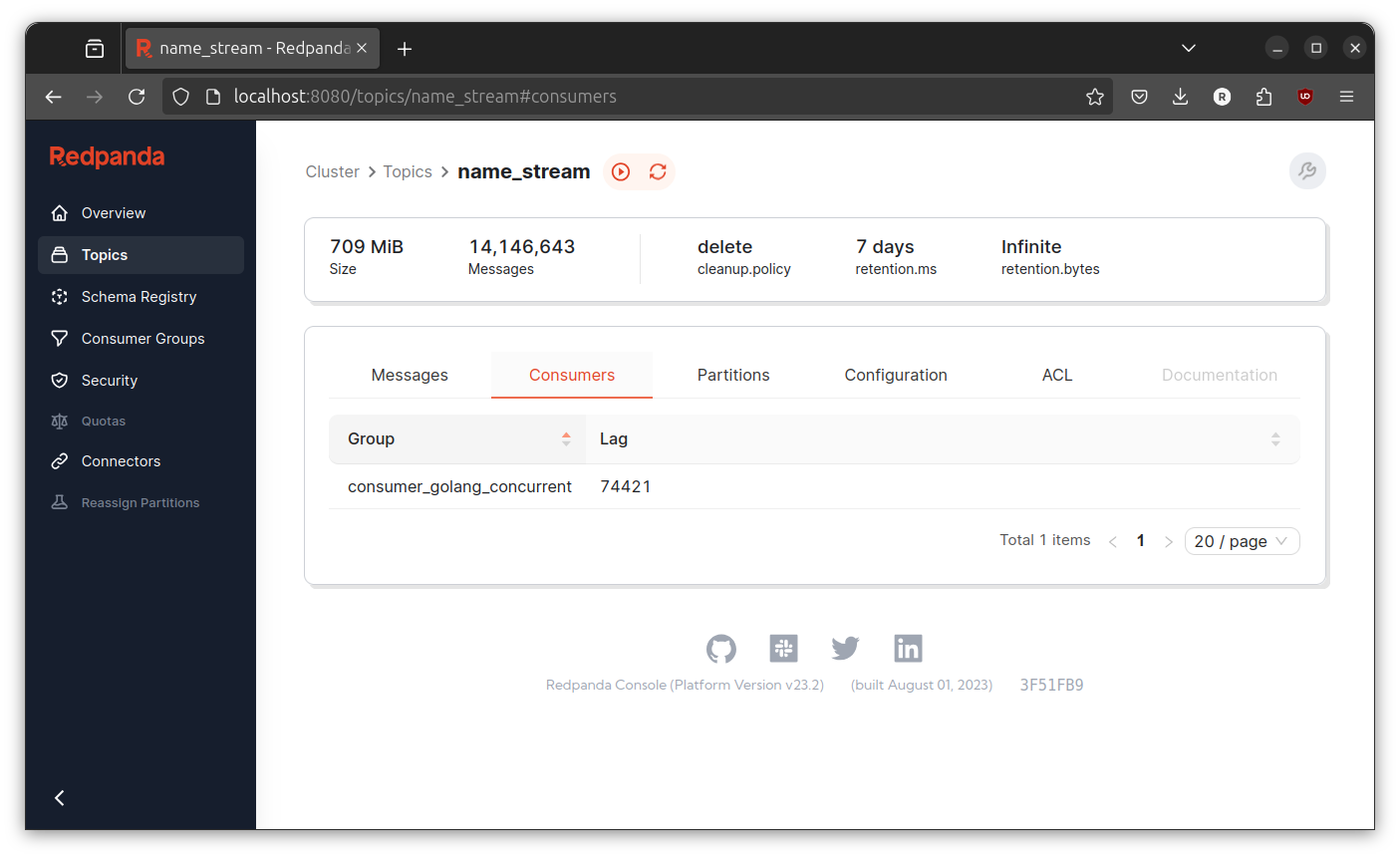
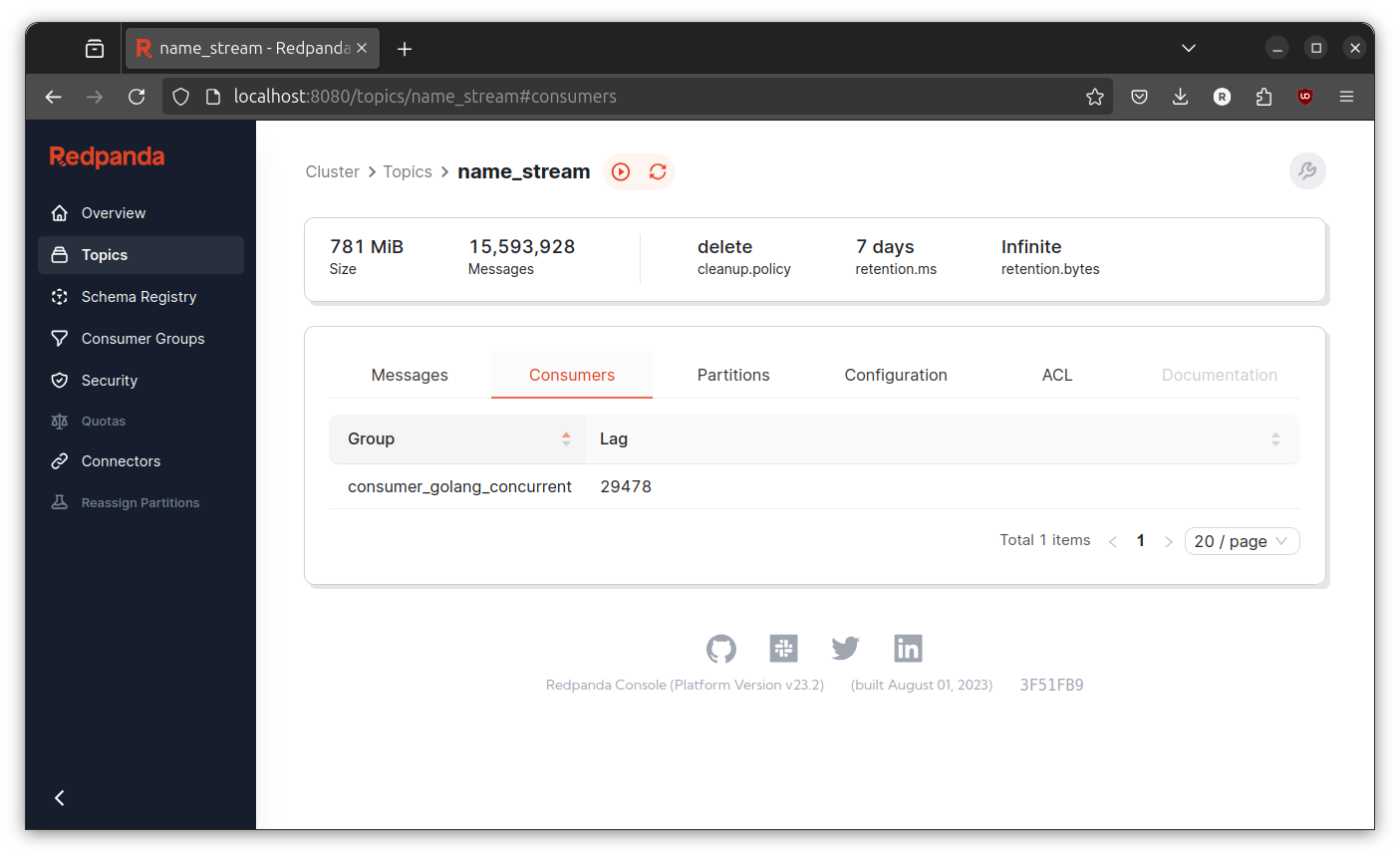
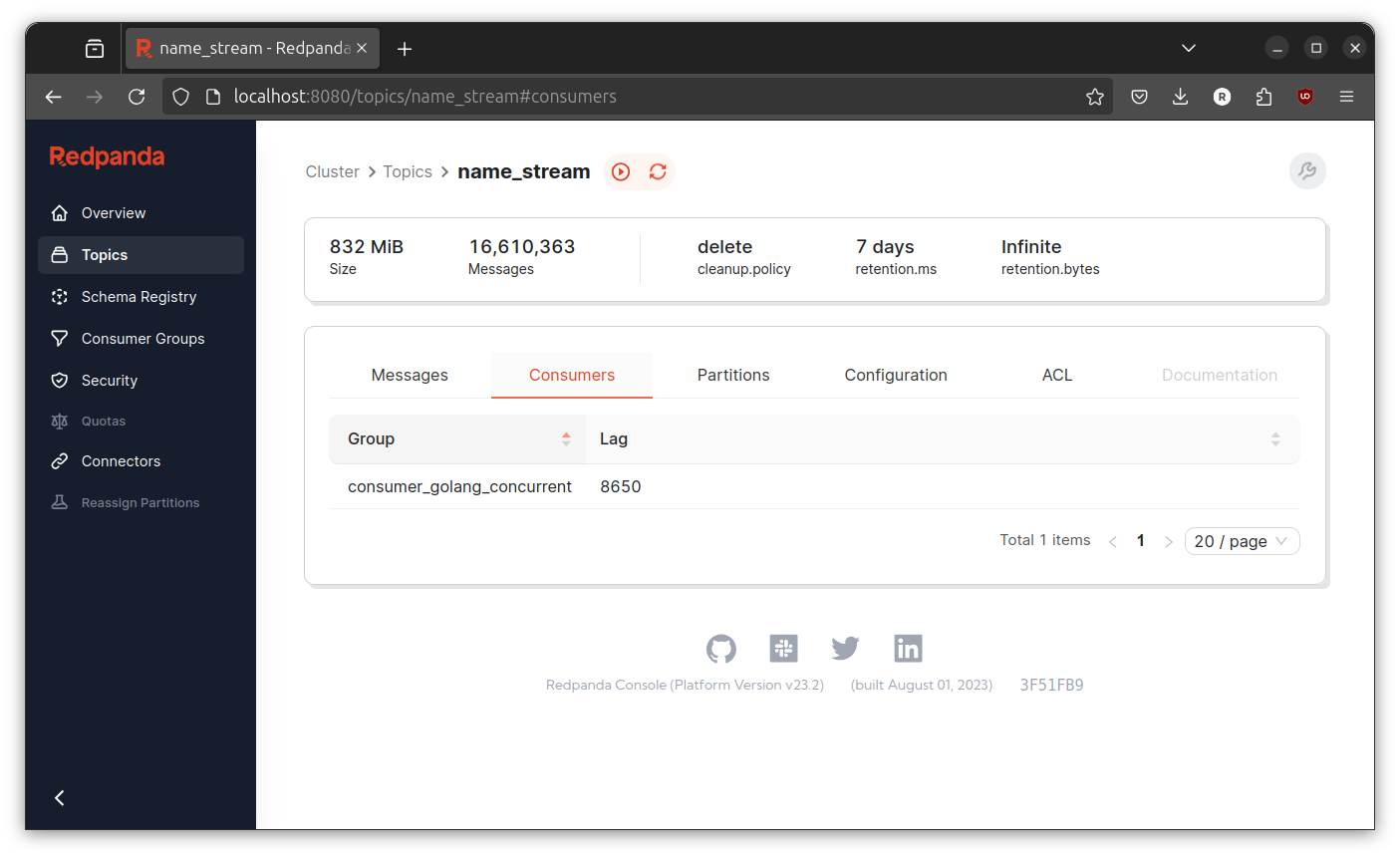
Again, sometimes its going higher sometimes lower. The only differences is now the number of consumer lag never touch above 500000. I guess the improvement is expected since the the number of worker is 4. But I don’t think it is 2x faster than the pipeline.
Anyway, I think that is from me. Personally, I really like the pipeline approach since it is preserve the order of the event and (I think) add a little bit of throughput. I can’t give exact number since I don’t measure the throughput. If you want to check on the source code, you can find it at https://github.com/rochimfn/resource-golang-transformer. Remember that the code is lack of proper error handling. No dead letter queue. Potential data lost if killed with 9 signal. No observability, and etc.
Thank you for reading and see you next time.